
Conozca (algo más) el CORPES
22 de Junio de 2021¿Sabía que el Corpus del Español del Siglo XXI (CORPES) contiene más de 1 500 000 lemas y más de 380 millones de elementos gramaticales? ¿Y que incluye más de 333 millones de formas ortográficas? Repasamos estos conceptos para poder utilizar mejor todo el potencial que esta herramienta ofrece a los usuarios.
Corpus y CORPES
Un corpus es un conjunto de (fragmentos de) textos, orales o escritos, producidos en condiciones naturales, seleccionados de modo que resulten conjuntamente representativos de una lengua o una variedad lingüística, en su totalidad o en alguno(s) de sus componentes, que se almacenan en formato electrónico y se codifican con la intención de que puedan ser analizados científicamente.
El CORPES es un corpus textual que responde a un determinado diseño, lo que lo diferencia de cualesquiera otras agregaciones de textos. Es un corpus general, un corpus de referencia, diseñado con la intención de que, al consultarlo, se puedan analizar fenómenos y elementos lingüísticos que se dan en una determinada lengua, en el español de España y de América en nuestro caso. CORPES incluye textos de diferentes características que garantizan que son muestras representativas y equilibradas del total de la lengua que representan. Los textos que forman parte del CORPES han sido producidos en España y en América, en español, durante el siglo XXI, es decir, desde 2001 a la actualidad.
CORPES —una herramienta que la RAE pone a disposición de todos los hispanohablantes en su página web— prevé en su diseño que cada uno de los años en los que se estructura cronológicamente esté representado por 25 millones de formas (palabras), de manera que, a medida que se construye, el CORPES incorpora textos del año en curso y también completa los años anteriores, por lo que combina las características propias de los corpus abiertos y cerrados.
La versión 0.93 del CORPES está formada por unos 316 000 documentos de una variada tipología textual. Se han incorporado textos de novelas, transcripciones de YouTube, noticias, tuits, publicaciones de blogs y de Instagram, guiones de cine, periódicos nacionales, revistas, libros de tecnología, de ciencias, de política…
El número de formas de cada uno de los textos incorporados a CORPES varía mucho. Por ejemplo, un tuit puede tener un número muy limitado de formas; algo más contiene una publicación de Instagram, y una novela puede llegar a superar las 130 000. Un artículo de deportes, una noticia, etc., rondan las 1000. Y una transcripción de una entrevista de unos 15 minutos, unas 2500 formas.
En la versión actual de CORPES todas las formas ortográficas contenidas en todos estos tipos de texto (y más) suman algo más de 333 millones. Una forma ortográfica es algo parecido a una palabra, es decir, el conjunto de caracteres que se encuentra, en un texto, entre dos blancos: en «entre dos blancos» hay, por tanto, tres formas ortográficas.
Anotación de CORPES
El CORPES ha sido sometido a un proceso de análisis lingüístico automático que tiene como objetivo asignar a cada palabra del corpus su correspondiente lema y hacer explícitos los valores morfológicos asociados a esa palabra. Ese proceso de análisis implica que, una vez identificadas las unidades de análisis (que generalmente coinciden con palabras, aunque también se identifican otras unidades complejas como expresiones idiomáticas, abreviaturas, verbos con enclíticos…), se someten a un proceso de lematización, es decir, de asignación de esa unidad al lema al que corresponde.
Después de ser lematizada, se analiza morfológicamente teniendo en cuenta el contexto lingüístico en el que aparece. El lema es la designación general para todas las formas integradas en un cierto paradigma. Por ejemplo, las formas comemos, comí, comeré, comimos, etc., pertenecen al lema comer. Y a la categoría gramatical verbo.
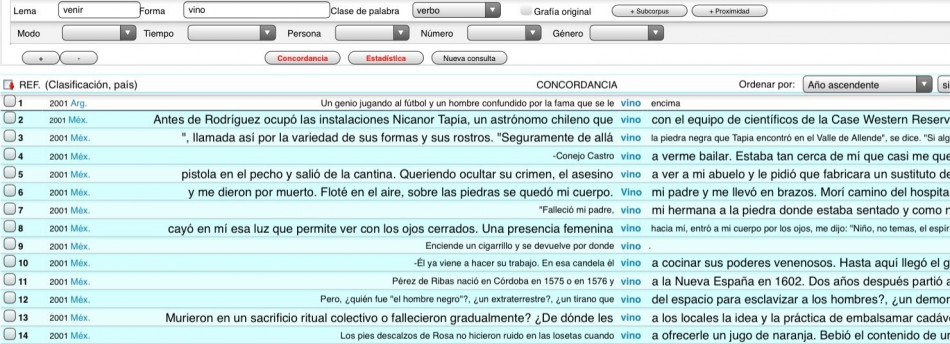
Así podremos distinguir vino (sustantivo masculino singular) de vino (tercera persona del singular del pretérito perfecto simple del verbo venir):
- De pronto ella se dio la media vuelta y vino hacia mí.
- Disfrutamos con la pasta, con el vino, con el fútbol, con el teatro y la pintura.
Este tipo de anotación permite a los especialistas la búsqueda de ejemplos en el corpus usando conceptos lingüísticos abstractos. Por ejemplo, podemos buscar sustantivos en femenino plural en todo el corpus, o seleccionando países, zonas, temas… tanto en textos escritos como orales.

Elementos gramaticales y lemas
En resumen, los elementos gramaticales son los que resultan cuando se llevan a cabo los procesos de análisis morfosintáctico. Se reconocen tres elementos en diciéndoselo (el gerundio diciendo, el pronombre se y el pronombre lo), mientras que Real Academia Española se considera una unidad.
Los lemas son las «palabras léxicas» a las que son adscritas las diferentes formas flexionadas o conjugadas. Así, llegué, llegaremos, llegarán, etc., son todas ellas formas pertenecientes al verbo llegar, que es el lema.

Si se considera también la clase (militar puede ser un verbo, un adjetivo o un sustantivo), en el CORPES hay 1 645 285 lemas distintos; 1 202 264 corresponden a nombres propios, así que el número de lemas diferentes realmente significativo es la diferencia: 259 838. En cierto modo, ese es el número de palabras diferentes que se utiliza en nuestro idioma, tanto en España como en América.
Con el sistema de anotación aplicado a la versión 0.93, el CORPES contiene un total de 383 906 287 elementos gramaticales, de los cuales 49 503 980 corresponden a signos ortográficos (puntos, comas, etc.).


